

計算で挑む環境研究—シミュレーションが広げる可能性 7 より速く、より多く、より長く、より複雑に —シミュレーションを支える技術—
現在、コンピュータシミュレーションは環境研究を支える重要な研究方法となっています。天気予報や災害の予測など、私たちの日常生活と深く関係していることもあります。
シミュレーション研究の内容は多岐にわたり、日々進歩しています。このシリーズでは、環境研究におけるシミュレーション研究の多様性や重要性を紹介いたします。
私は、数値モデルシミュレーションとデータ同化技術を組み合わせて、温室効果ガスや大気汚染物質の濃度や放出量をより正確に再現するための研究をしています。それと同時に、より精度の高いシミュレーションを行うための数値モデルそのものの改良を行っています。今回は、この連載で他の著者の皆さんが紹介する「現実の世界」と「シミュレーション」を繋ぐ話からさらに潜って、「シミュレーション」と「コンピュータ」に関わる研究を紹介しようと思います。
1. シミュレーションと気象・気候学
科学はまず、自然の観察から始まりました。目に見えている世界は、たとえそれが宇宙のどこででも、同じルールに従って動いているに違いない。そのルールを探すことを出発点に、科学研究は発展してきました。自然を相手に実験や観測を繰り返すことで、その中から理論を導き出し、そして理論を元に新たな理論を発見したり、新たな実験のアイディアをひらめいたりしてきたのです。この「実験・観測」と「理論」は、科学を支える大事な2つの手法です。
そうしているうちに、科学者は考えました。これまでに得られた沢山の理論・法則を組み合わせることで、自然に起こることを再現できないだろうか、と。これが第3の科学的手法と呼ばれる「模擬:シミュレーション」です。自然は複雑で、いろいろな現象が同時に起こっています。そのため、シミュレーションではたくさんの方程式を連立させて解く必要がありました。
また、多くの場合、再現したい現象は時々刻々と変化し、方程式から一意に解を得られるものではありません。その場合は、時間発展する連立方程式に実際に数値を代入して、次の時刻の状態を順次計算するという方法をとらざるを得ません。そのため、科学の世界でシミュレーションといえば数値シミュレーションであるし、イコール数値計算を指すことが一般的です。
最初のシミュレーションは、人間が紙と鉛筆または手回し式の計算機を使って行われ、たとえば航海の進路や、天体の運行、砲弾の軌道を推定していました。17世紀から1970年代までは、このような計算を行う人の職業を「コンピュータ(計算手)」と呼んでいたそうです。
かつてNASAで伝説的計算手として働いていたキャサリン・G・ジョンソンさんらを題材にした「ドリーム(原題:Hidden Figures)」という映画が2016年に公開されています。ご興味のある方は是非ご覧ください。1970年代初頭の宇宙開発を支えていた計算手という職業、そして「コンピュータ(計算手)」と「コンピュータ(IBM)」が入れ替わろうとしていた時代が垣間見えると思います。
気象学では、イギリスの気象学者ルイス・F・リチャードソンが第一次世界大戦中に、ヨーロッパ中央部の気圧の予報を試み、ひとりで6週間かけて6時間先の値を得たそうです。この時の結果は方程式にまだ科学的な理解が進んでいなかった不備があり、残念ながら現実的な気圧の再現には至りませんでしたが、リチャードソンは1922年の著書(写真1)で、巨大な劇場に何万人もの計算手を集めて気象計算を行えば気象予報は可能になる、と提案しました。これは「リチャードソンの夢(Richardson’s Fantasy)」として有名です。
電気で動く現代のコンピュータに近いものが登場したのは、第二次世界大戦後の1946年、なかでもENIAC(Electronic Numerical Integrator and Computer、写真2)が有名です。このENIACを用いて、気象学者のジュール・G・チャーニーらが数学者ジョン・フォン・ノイマンと協力し、北米領域の気象予報を成功させました。リチャードソンの試みから30年後、気象学と電子計算機の両方が発展した結果であり、今から70年前のことです。
それからわずか10年で、電子計算機は各国の気象機関に次々と導入され、今日も最新鋭のスーパーコンピュータ(スパコン)が世界中の気象予報を支えています。黎明期から現在に至るまでずっと、気象気候分野の科学者はコンピュータのヘビーユーザーです。
気象・気候・環境の科学にとってシミュレーションが欠かせない理由は明快です。私たちの住む地球がひとつしかないからです。過去にもしもこんなことがなかったら今はどうなっていただろうか、今こういうアクションを起こせば未来はどう変わるだろうか。現実の世界で地球規模の試行錯誤を行うことはできません。しかし、確かであると皆が認める科学法則を組み合わせた地球の模型(モデル)を構築できれば、バーチャルな世界で好きなだけシミュレーションを行って、現実の世界に役立てることが可能になります。
また、実際の観測が難しい現象も、シミュレーションを通して知ることができます。たとえば、研究所がある茨城県つくば市で今日降った雨が、何日前にどこで蒸発した水なのかを知るのはかなり大変です。しかし、シミュレーションでは水蒸気の流れを追いかけて、定量的に調べることができます。


2. 気候シミュレーションの再現精度を決める重要な要素とは?
シミュレーション結果が現実をよく再現してくれるかどうかは、とても重要です。しかし、シミュレーションは多くの場合、現実と完全には一致しません。では、何がシミュレーションの精度を左右しているのでしょうか。
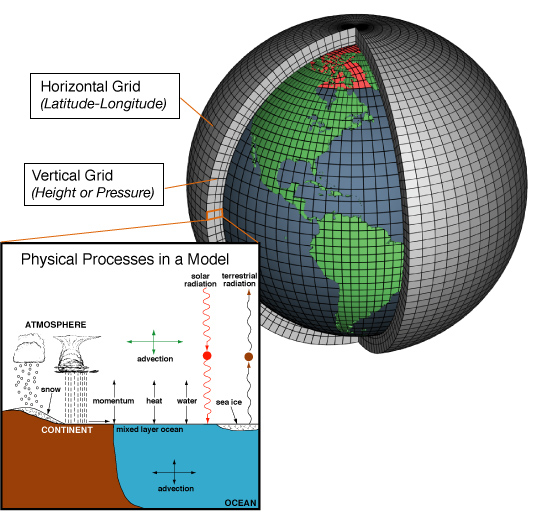
精度を左右するもののひとつは、必要な要素が過不足なく表現されているかということです。たとえば、大気には流れ(いわゆる「風」)があります。大気は地面や海から熱や物質を受け取ったり、逆に渡したりします。一方、水蒸気は冷えると雲になって、雨や雪を降らせます。雲は太陽からの光を遮りますし、オゾン層は紫外線を吸収して大気を暖めます(これにより有害な紫外線を地上に到達させません)。また、大気は温度に応じた赤外線を宇宙に向かって放出し、太陽光として入ってくるエネルギーと出ていくエネルギーをバランスさせようとします(図1)。
ここに挙げた要素はほんの一部で、シミュレーションを実現するために必要な要素がたくさんあります。これら要素一つひとつを全体から細部に向かって列挙し、モデルを組み立てていきます。将来の気候変動をシミュレーションするには、大気のモデルだけでは足りなくて、海洋のモデル、陸上生態系のモデルなど、個々に開発されてきたモデル同士を結合してひとつの大きな「地球システムモデル」を作る必要もありました。
必要な要素を揃えたら、今度はそれぞれの要素ごとの「確からしさ」が重要になってきます。モデルはあくまで「模型」で、コンピュータ上に地球のコピーをまるごと作れているわけではありません。たとえば、大気の流れを再現するために、およそ10の44乗個もある大気中の分子の一つひとつの動きを計算するわけではなく、大気を分子が集まった「流体」とみなす、という簡略化を行っています。
このように、物理現象をちゃんと表現できる程度に簡略化することがモデル化にとって重要です。そうしないと、コンピュータで現実的に計算できる計算量、データ量を超えてしまうからです。
コンピュータの性能がまだ十分でなかった頃は、かなり思い切った簡略化を行っていました。たとえば、二酸化炭素(CO2)による温室効果を世界で初めて数値シミュレーション結果で世に知らしめた、真鍋淑郎先生の1967年の論文の中で使われた大気モデルは、3次元ではなく1次元(高さ方向)だけしかありませんでした。それでも地球大気の気温の鉛直分布がCO2の濃度によって変わることを説明するのには十分だったわけです。
では今も簡略化されたモデルで十分かといえば、そうではありません。現代の私たちが明らかにしようとしていることには、50年前よりも時間・空間的により詳細で、高い精度が求められているからです。
コンピュータの性能向上と共に、再現精度を犠牲にした簡略化をやめて、より精緻化されたモデル(の部品)を使うようになってきました。中でも、大気や海洋のシミュレーションで一番重要だといっても過言ではないのが、空間解像度です。
図1に示したように、大気モデルは地球を覆う球殻上の大気を3次元の格子で分割して、それぞれの格子点での大気の状態を計算します。格子間隔が粗いと、起こっているはずの現象が見えなくなってしまいます。たとえば、100 kmメッシュ間隔だと、首都圏と東京湾がまるまる入る領域に、計算する格子点が1点しかありません。これでは台風の形もわからないし、「晴れている」「曇っている」場所の区別もかなり大ざっぱになってしまいます。
また、100 km四方の平均値では「相対湿度が100%になっていない」=「雲が生まれない」と判定してしまうけれど、実際には「とても狭い領域で雨が土砂降りになっている」、なんて齟齬が生まれます。粗いモデルでは極端現象を捉えられないのです。
「よし、では空間解像度を上げよう!」と思っても、それはなかなか容易なことではありません。100 kmメッシュ間隔を10 kmメッシュ間隔にすると、水平方向の格子点の数は100倍に増えます。さらに、格子点の間隔が狭い場合、一般的にシミュレーションの時間刻みを小さくしないと数値計算は破綻することがわかっています。
この10 kmメッシュの例だと、時間刻みも10倍細かくしなければいけません。そのため、同じ時間だけシミュレーション内の時間を進めようとすると、10倍のステップ数が必要となるのです。結果として、解像度を10倍上げると、計算量は10の3乗 = 1000倍多くなります。もし100 kmから1 km解像度まで100倍解像度を上げたら、計算量は100万倍になります。
3. 計算機の目覚ましい発展
「気象・気候のシミュレーションを根本的に改善するには、1000倍も100万倍も性能が高いコンピュータが必要なんだ!」という理由はわかって頂けましたでしょうか。
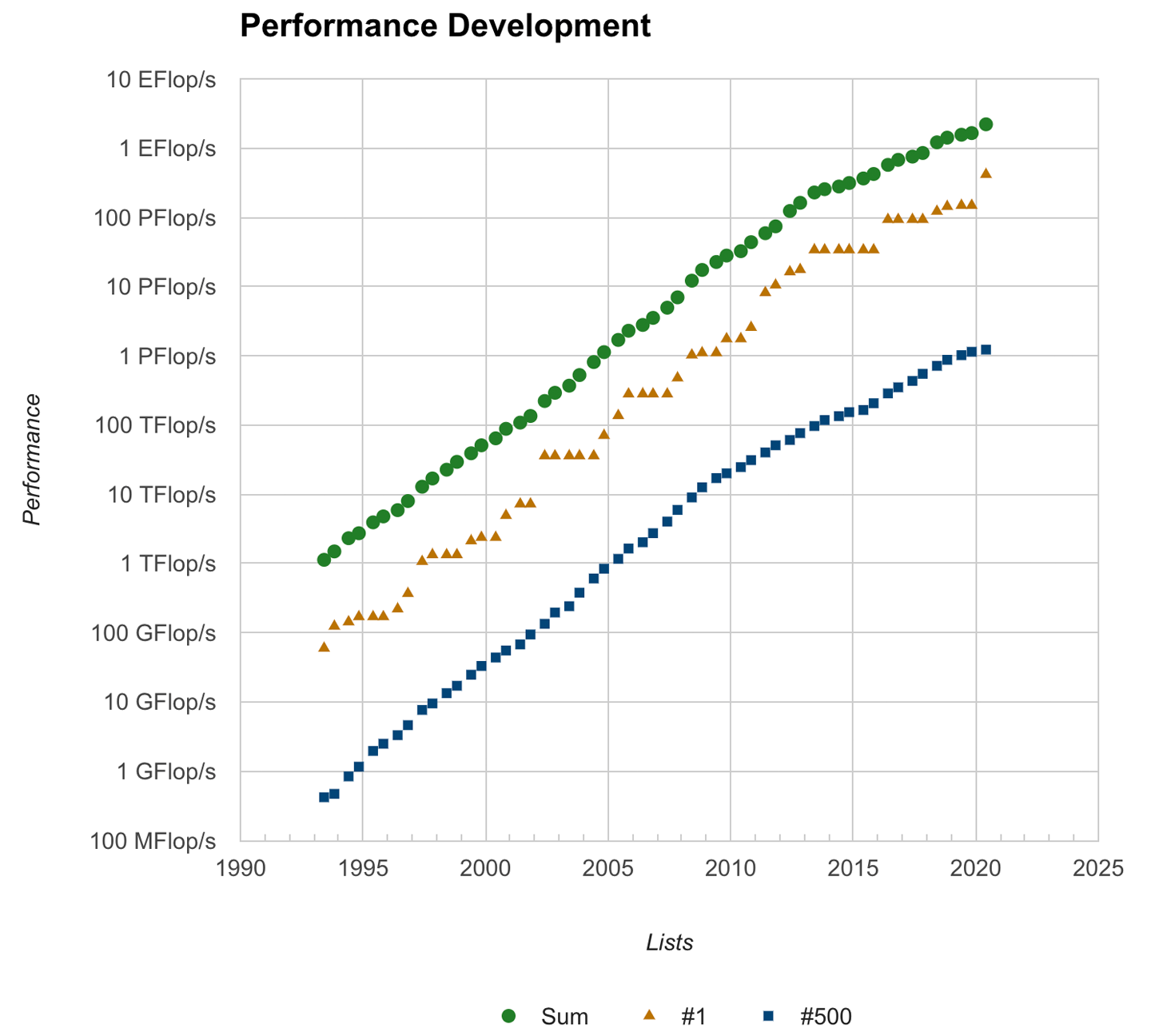
では、今度はコンピュータの世界に目を移してみましょう。スパコンの世界では年に2回、計算性能を競う「Top500」というコンテストがあります。国際的なルールに則って、膨大な数の連立方程式を解くプログラムの速さを「1秒間あたりの浮動小数点演算数(Floating Operation per Second, FLOPS)」という指標で測ります。
Top500は1993年からずっと続けられてきていています。1993年当時の世界1位のスパコンの性能は約60ギガFLOPSでした。では、2020年の世界1位のスパコンの性能はいくつでしょう。416ペタFLOPSです。27年でおよそ690万倍!ですね。人類の進歩においてこれほど急速に性能が向上した産業は電子計算機以外にないといわれています。そのスピードは、おおむね1.5年で性能2倍、10年でおよそ100倍のペースです(図2)。
ちなみに、1993年の500位のスパコンの性能は0.4ギガFLOPSでした。今の最新のスマートフォン(iPhone11)で同じベンチマークを行うと、2ギガFLOPSの性能が出ます。私たちは25年前のスパコンを手のひらサイズで持ち歩いていることになります。1.5年でコンピュータの性能が2倍になるという経験則は、インテルの共同設立者であるゴードン・ムーアさんが発見したため、「ムーアの法則(Moore’s Law)」と呼ばれています。
コンピュータは生まれてから今まで、着実に性能を上げ続けてきました。しかし、その道は平坦なものではなく、いくつもの技術的困難を乗り越えてきました。
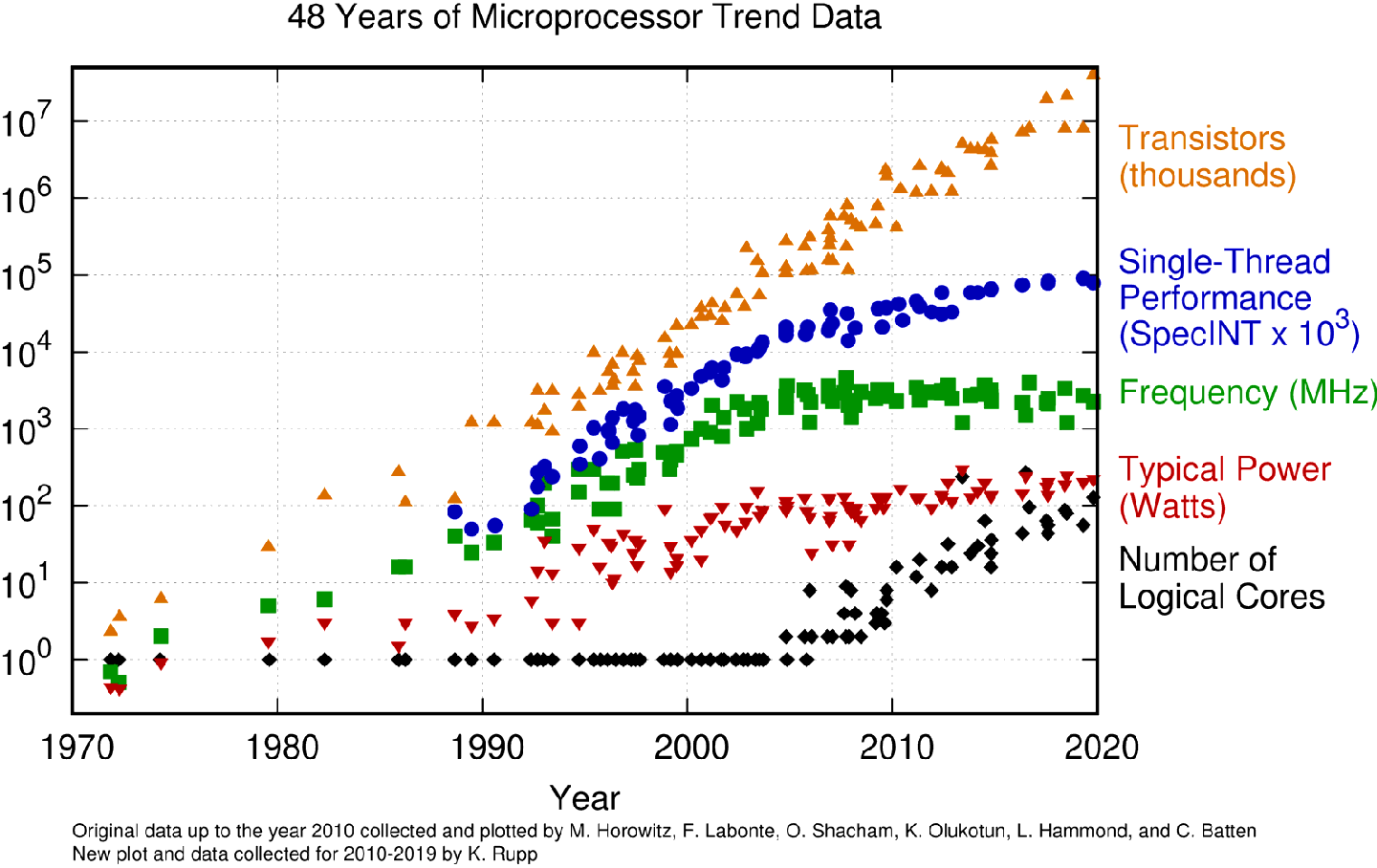
下に示す図は、かなりマニアックですが、ここ40年くらいのコンピュータの演算装置(プロセッサ)に関する各種指標の時系列を示しています。上から順にスパコンのトランジスタの数、中央演算装置(CPU)に含まれる「コア」と呼ばれる構成単位あたりの演算性能、CPUの動作周波数、消費電力、そしてコアの数です。
一般的には、CPUの性能を向上させるには、配線の長さをなるべく短くする、動作周波数を上げる、といった方法があります。このうち、配線の長さを短くする方法は同時に消費電力を削減するので、どんどん経済的かつ高性能になっていくので素晴らしいです。しかし、微細加工の技術はすぐに進化していくわけではなく、細かくなるにつれてますます困難になっていきます。今のCPUの配線の長さは数ナノメートル単位で、もう電子顕微鏡でないと見ることができない世界です。
動作周波数を変える方法はというと、周波数を上げると指数関数的に消費電力がどんどん増えていってしまうという問題があります。そのため、動作周波数の増大は2000年あたりを境に諦められてしまいました。その代わりに同じ「コア」をたくさん並べて同時に計算させることで、性能を向上させようという試みが主流になりました。皆さんのパソコンでも、20年前は「このCPUは何ギガHzですごい」といわれていたのですが、今は「何コア積んでるからすごい」といわれるようになりました。
もう一つ、CPUの性能を決める要素として重要なのが、SIMD(Single Instruction Multiple Data)演算、あるいはベクトル演算と呼ばれるしくみです。一回の機械語の命令で、同時に複数のデータを処理できる方が、電力性能が高く演算速度を高めることができるのです。これによって、コアあたりの演算性能も年々向上してきました。
そして、計算を実行する速度の他にもう一つ、コンピュータの性能を決める重要な要素があります。それはデータの移動速度です。
一般的に、データを高速で移動させるデバイスは高価です。そのため、容量をあまり多く確保できません。つまり、速いと容量が小さい、容量が大きいと遅い、ということです。前者の代表格はメモリ、後者ならハードディスクドライブ(HDD)です。CPUの中にはメモリよりもさらに高速で小さなキャッシュメモリと呼ばれる一時記憶領域があります。
さて、ここで問題が浮上しました。現代のスパコンにおいて、計算の処理速度を上げるには「並列」が重要だと先程申しましたが、並列に処理するためのデータを、一度に、速く取り出してくるにはどうしたらよいのでしょう?
両方を同時に満たそうとすると、マシンはものすごく高価になってしまいます。このように、現代のスパコンはあっちを立てればこっちが立たない、さまざまなトレードオフの中で、最適なマシンを作っていかなければいけないのです。また、近年は、もともと画像処理用に特化した補助装置であったグラフィック演算装置(GPU)を科学計算に用いるようになりました。GPUはトレードオフがある中で思い切った取捨選択を行い、消費電力性能や計算速度を向上することに成功しました。でも、同時に苦手なことがあるというのも確かです。
4. 現代のスパコンで気候シミュレーションを高速化したい
さて、コンピュータの世界では絶え間なく性能を伸ばすために、大胆な進化を何度も行ってきたわけですが、それではそのコンピュータの上で動作させる気象・気候モデルはそのままでよいのでしょうか? 答えはNOです。ソフトウェア側も絶えず変革しなければ、最新のスパコンの性能を活かすことはできません。とはいえ、私たちがモデルの高速化のために行ってきた基本の2つの手法は、前述のコンピュータの性能トレードオフと密接に関連しているため、あまり変化していないともいえます。
ひとつは「並列化」です。今のスパコンはCPUを何千、何万と並べて、計算を同時並列で行うことで計算速度を向上させています。前述のとおり、CPUの内側にもさらに複数のコアがあり、さらにそのコアの中でSIMDというしくみによって一度に複数のデータを並列で処理しようとします。
モデルを開発する側は、用いるアルゴリズムの中にデータを独立して処理できる部分、すなわち「並列性」を見いだす必要があります。しかも、現代のコンピュータのスタイルに合わせて、「階層化された並列性」をうまく作り出す必要があるのです。たとえば、私たちの開発する大気モデルNICAM(Nonhydrostatic ICosahedral Atmospheric Model)では、大気を水平方向に大きく分割して別々のCPUに割り当て、さらに鉛直方向の大気の層を別々のコアに割り当て、水平方向に並んだ格子点をなるべく同じ方法で計算しています。
しかし一部では、鉛直方向に順々に計算を進めていく必要があるため、並列に計算ができず、そのままでは性能が上がりません。こんなときは水平方向の並列性を用いて階層化を行うなど、また別の工夫が必要になります。
もうひとつの高速化手法は「データの局所化」と呼ばれます。前述の通り、より転送速度が高い記憶領域は容量が小さく、よりCPUに近いところで使われており、CPUから遠くなるほど遅くて容量の大きい記憶領域(メモリやHDD)が使われています。計算に必要なデータは遠いところから順に運ばれてきて、計算が終わるとまた順に遠い記憶領域に戻って格納されます。つまり、一度計算に使ったデータが速いメモリに留まっている間にうまく使い回すことができれば、データの移動にかかる時間を短縮することができるのです。
物理法則に則って組み立てられたアルゴリズムは、多くの場合、研究者の頭の中で考えた通りの順番で計算を進めようとして書かれています。そこからさらに計算機のことを考えて、用いる変数(データ)の「依存性」や「賞味期限」を意識し、計算する順番を入れ替えたり、一時的に格納する中間変数を増やしたり減らしたりすることが、コンピュータの性能を活かす上で重要になってきます。
ここで先程の問題が再び浮上してきます。十分な「並列性」を保つために一度に準備しないといけないデータの数は年々増えていくのに、「データの局所化」というのは一度に準備するデータの容量が小さいほど効率的であり、つまり、ふたつの基本的な最適化手法はお互いに相反するものです。そのため、スパコンのハードウェアと、気象モデル等のソフトウェアがお互いにトレードオフを意識しながら、最適な解を探していく「コデザイン」という取り組みが重要なのです。
気候モデルはさまざまな分野の研究者が学際的に集まって作り上げた巨大で複雑なプログラムです。それゆえに、ソフトウェアの最適化はとても骨が折れる作業です。さらに、最適化を進めていく中で、私たちは気象・気候モデルのとても厄介な特徴を認識するようになりました。それは「プログラムの中に、計算時間と計算量の大部分を占めるような代表的区間がない」ということです。
他の科学分野では、基礎方程式の数も、プログラムで扱う変数の数も、気候モデルよりずっと少ないことのほうが多いのです。また、主要な基礎方程式を解く部分が全体の計算時間の半分以上を占め、そこさえチューニングすればかなりの性能向上が見込める、といったこともしばしばです。
ところが気候モデルには、アルゴリズム的な性質の異なる計算が多数あり、どれもあまり多く計算することなく次の変数の計算に移ってしまいます(このことを「演算密度が低い」といいます)。結局、プログラム中のあらゆる区間が少しずつ時間を消費していることになり、最適化のためには数十万行あるプログラムコードのすべてに目を配らなければ速くならないのです。
私たちは日本が誇るスーパーコンピュータ「京」や「富岳」といった計算機を用いて全球高解像度大気モデルNICAMの最適化を進めるなかで、このような厄介な性質をもつ気候モデルを効率よく最適化する方法を開発しました。
最も効果的だった手法は、まるで家計簿のように、すべてのプログラム区間が消費する時間を一度に並べあげ、プログラムコードの中に小さくたくさん散らばっている「無駄な支出」=「減らせるはずの消費時間」がないかをチェックする方法でした。
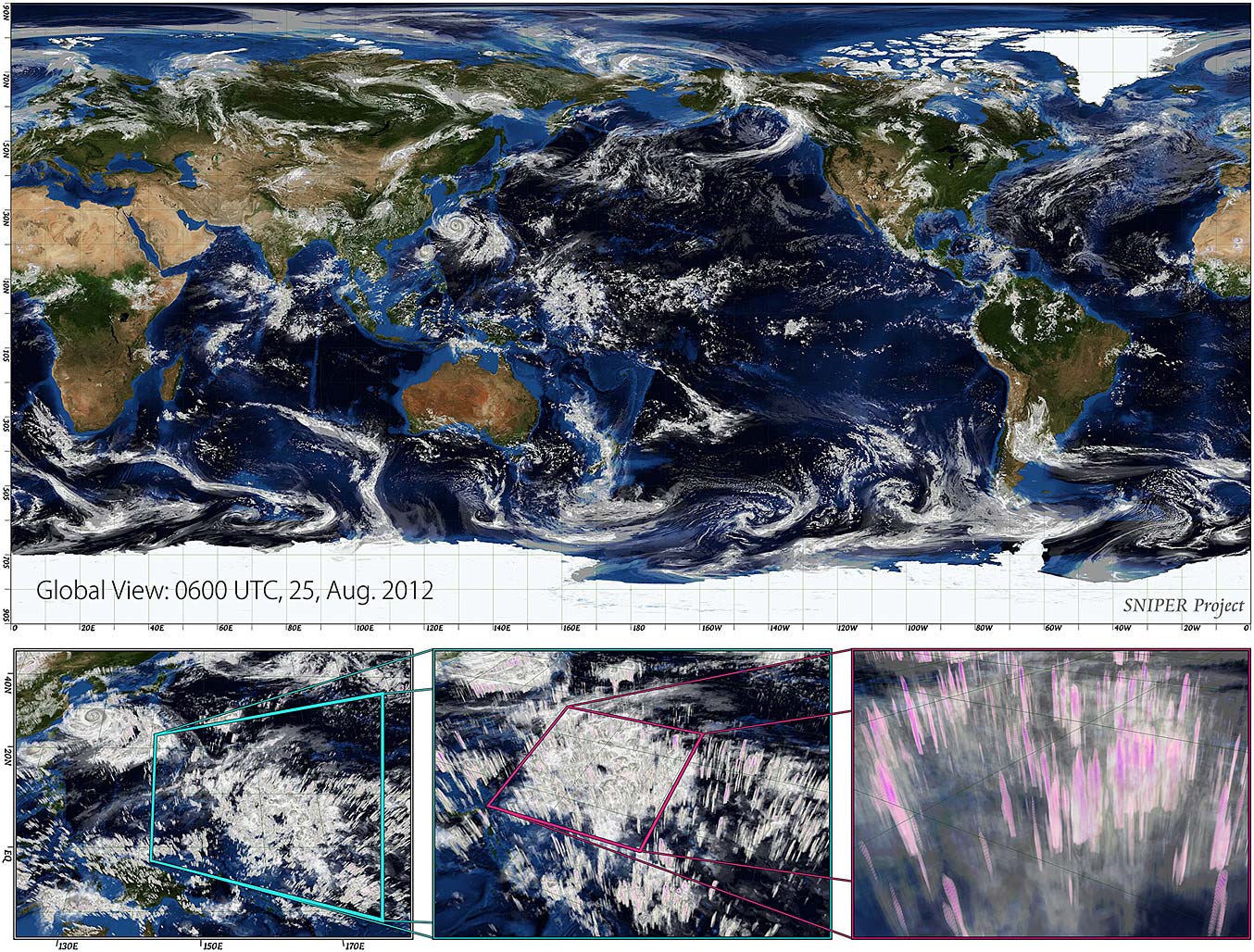
こうしてNICAMは現代のスーパーコンピュータの性能をうまく引き出すことができるようになり、「京」を用いた計算では、当時世界で初めて1 kmを切るメッシュ解像度での全球大気シミュレーションを、2万個のCPU(16万個のコア)を用いて実現しました(図4)。このとき、モデルの格子点の数は630億点、シミュレーション内の時間で1時間計算するのには4時間かかり、この時の実効計算性能はおよそ230テラFLOPSでした。また、48時間のシミュレーションで320テラバイトの時系列データを出力しました。
5. スーパーコンピュータ「富岳」と気候モデルのコデザイン
2019年にその役目を終えた「京」のあとを継ぎ、新たな日本の旗艦スーパーコンピュータである「富岳」が、もうすぐ運用を開始します。富岳は設計当初から、単純なベンチマーク結果ではなく、実際の科学シミュレーションでの性能が向上することを重要視して開発が進められ、さまざまな科学分野のアプリケーションソフトウェアとのコデザインを行ってきました。
気象・気候分野からはNICAMだけでなく、気象予報や温室効果ガス排出量推定に用いられる「データ同化」の分野からアンサンブルデータ同化システムの一つであるLETKF(Local Ensemble Transform Kalman Filter)が選定され、シミュレーション科学とデータ科学の複合アプリケーションとしての性能向上を進めてきました。
富岳でのグランドチャレンジとして、3.5 kmメッシュの異なる1024個の大気シミュレーション結果と、全球の気象観測情報を用いた全球高解像度・大アンサンブルデータ同化実験を予定しています。総格子点数はのべ4兆点、大気モデルが出力するデータ量は1ペタバイトにも達します。これはこれまでに人類が誰も到達したことのない規模の気象シミュレーションです。富岳はハードウェアの設置が2020年5月に完了し、さまざまな性能の調整が今まさに行われているところです。
富岳の時代の気候モデルは、また新しい計算科学的な課題に直面しています。シミュレーションの速度をさらに上げていくには、今までとは異なるアプローチをする必要が出てきました。
その一つが「データ転送を減らす」ということです。前述の「データの局所化」も、データをなるべく長くCPUに近い、速い記憶領域にとどまらせることで、データ転送を減らそうとしていたのですが、さすがにもうやれる工夫にも限度がきています。ならば、データを移動させる量を別の方法で減らすしかありません。私たちが今有望だと思って取り組んでいるのが、モデルの中で用いられている浮動小数点実数の桁数を減らそう、という試みです。
科学計算ではよく単精度実数、倍精度実数という言葉が出てきます。それぞれ実数を4バイト、8バイトの2進数で表すもので、表現できる数の範囲は、倍精度実数の方が広いです。倍精度実数だとおおむね有効数字が16桁ぐらいあると思って利用しています。
これに対して単精度実数では有効数字は8桁しかありません。しかし、データサイズは半分になります。サイズが半分なら転送量も半分になり、転送時間を半減させられるし、同時に小さくて速い記憶領域により多くの変数を留まらせることができるようになります。さらに、同時に処理するデータの数も倍に増やすことができるのです! これは素晴らしいことなのですが、一方で、有効数字桁数の少ない実数で計算を行えば、シミュレーションの精度は落ちてしまいます。
今度は計算速度とシミュレーション結果とのトレードオフを考えながら、私たちは最適な解を探そうとしています。そしてその先はもっと桁数の少ない実数(たとえば、半精度と呼ばれる2バイト実数)が使えないかを模索しようとしています。
もう一つは、いま流行りのAIの活用です。気候モデルの中の複雑で長いアルゴリズムを、機械学習によって得られた巨大なニューラルネットワーク(NN)に置き換えてしまおうという試みが行われています。気候モデルの部品には大小さまざまな簡略化モデルが入っています。観測結果や、より精緻化されたシミュレーション結果を用いてトレーニングを行ったNNは、それらの簡略化モデルと同等、あるいはそれ以上の再現性能を発揮することが期待されます。NNは計算時間を劇的に短縮するのと同時に、今まで不確実性を減らすのに苦労していた簡略化モデルの原因を新たな視点から見直し、改良するためにも用いられます。
空間解像度の低いモデルシミュレーションは計算が軽くて高速ですが、簡略化モデルの不確実性が将来予測に大きな影響を与えます。一方で、空間解像度の高いモデルシミュレーションは再現の不確実性を減らすことができているのですが、計算が重くて長期の将来予測を行うのは大変です。AIを用いたデータ科学でこの両方の利点をうまく活かし、さらに精度の高い将来の気候予測、環境予測を進めていくことを考えています。